
This page provides frequently-asked questions about the Trafodion project and their answers.
Project
What is Project Trafodion?
Project Trafodion is an open source initiative originally cultivated by HP Labs and HP IT to develop an enterprise-class SQL-on-HBase solution targeted for big data transactional or operational workloads as opposed to analytic workloads.
When is Trafodion available?
Trafodion is currently available at downloads.trafodion.org. There, you can find an installer and executable code. For installation instructions, see Installation.
What are the key features of Trafodion?
The key features are:
- Full-functioned ANSI SQL language support
- JDBC/ODBC connectivity for Linux/Windows clients
- Distributed ACID transaction protection across multiple statements, tables and/or rows
- Transaction recovery to achieve database consistency
- Optimization for low-latency read and write transactions
- Support for large data sets using a parallel-aware query optimizer
- Performance improvements for OLTP workloads with compile-time and run-time optimizations
- Distributed parallel-processing architecture designed for scalability
What are the key benefits of Trafodion?
Trafodion delivers a full-featured and optimized transactional SQL-on-HBase DBMS solution with full transactional data protection. These capabilities help overcome basic Hadoop limitations in supporting transactional workloads.
With Trafodion, users gain the following benefits:
- Ability to leverage in-house SQL expertise versus complex MapReduce programming
- Seamless support for existing transactional applications
- Ability to develop next generation highly scalable, real-time transaction processing applications
- Reduction in data latency for down-steam analytic workloads
- Adoption of data reuse by different application domains
And operational SQL users also gain the following benefits inherent in Hadoop ecosystem.
- Reduced infrastructure costs
- Massive scalability and granular elasticity
- Improved data availability and disaster recovery protection
Why is it called Trafodion?
Trafodion is Welsh for transactions.
What are the primary use cases for Trafodion?
Primary use cases on Trafodion consist of existing HBase workloads enhanced through SQL with transactional data protection. Another class of use cases consist of new or rehosted existing operational applications to address scalability issues, complex application programming, or prohibitive licensing costs.
What is the heritage of the Trafodion software?
Trafodion is based on HP’s 20+ year history in developing database products for OLTP. Building on this heritage, Trafodion provides distributed transaction management protection over multiple SQL statements, multiple tables and multiple rows.
What do you mean by “Transactional or Operational SQL”?
Transactional or Operational SQL describe workloads were previously described simply as OLTP (online transaction processing) workloads. This expands that definition from the broad range of enterprise-level transactional applications (ERP, CRM, etc.) to include the new transactions generated from social and mobile data interactions and observations and the new mixing of structured and semi-structured data.
Using
Why would Trafodion be used over a commercial OLTP database?
Trafodion is an open source product and like other products in the Hadoop ecosystem, it obtains two key advantages over the tradional proprietary OLTP database systems: Cost structure and Data reuse.
Is Trafodion mainly an extension to HBase?
Not quite. Trafodion runs on top of HBase using the HBase APIs to perform the typical SQL functions of insert, update, delete, and query data with transactional protection. However, there are plans to include database capabilities using the coprocessor mechanism provided by HBase.
Besides data access via SQL database connection, what other advantages does Trafodion offer over existing distributed database technologies?
With Trafodion, users can make use of standard HBase APIs as well as use Trafodion for SQL access to the HBase tables. This includes Trafodion’s ability to use powerful SQL capabilities to do joins against both HBase and Trafodion tables and run queries against them while providing transaction management capability.
This allows application developers to choose the best access methods for each particular data usage, based on skill set, data size and usage, and access pattern requirements.
Can Trafodion modify tables?
Yes, Trafodion provides full-featured ANSI DML operations including INSERT, UPDATE, DELETE, MERGE, and UPSERT statement support.
What is the benchmarked performance for a transaction workload?
Benchmark results will be posted as the community publishes them.
Where would you position Trafodion according to the CAP theorem? Is it CP (consistent and partition tolerant as HBase) or CA (consistent and highly available)?
Trafodion is hosted on top of HBase and HDFS. HBase is generally viewed as being CA (Consistent, Available) in the context of the CAP theorem.
Unlike regular HBase, Trafodion extends the definition of consistency to provide ACID protection across transactions comprised of multiple SQL statements, tables, and rows.
How does Trafodion scale in terms of database size?
As Trafodion is hosted on HBase/HDFS, in theory, Trafodion’s database should scale as HBase/HDFS scales. To this point (due to available hardware limitations), Trafodion has been tested with configurations up to 10 nodes and 50 terabytes.
What about high availability? Does Trafodion have a single point of failure?
HBase and HDFS are considered highly available with many built in features for HA including name node redundancy, HDFS k-safety data replication, HBase replication, HBase snapshots, Zookeeper’s highly reliable distributed coordination of Hadoop hosted services, and so on.
Additionally, the planned release of HBase 1.0 is advertised as having many additional HA features which Trafodion incorporates as it supports HBase 1.0. Furthermore, many Hadoop distributions have added their own HA features at the HBase or HDFS layers.
Trafodion leverages HBase and HDFS capabilities for providing extended HA to the connectivity and SQL layers. For example, Trafodion registers its connection services using Zookeeper to ensure persistent connectivity services. Trafodion is designed as an MPP service with replicated service points for HA and no single points of failure.
Is Trafodion best suited for reads or for writes?
Trafodion provides a bulk load capability that interfaces directly with HDFS for high-performance data loading. HBase leverages large-scale cached memory to host data in memory until the HFile buffer becomes filled and is then written to HDFS.
Additionally, Trafodion provides many low-latency read optimizations on top of HBase to significantly improve the both the random and parallel read performance of the database engine. These include:
- Statistics-based plan generation
- Degree of parallelism optimization
- In-memory data-flow, scheduler-driven executor
- Query plan caching
- Key-based access with SQL “pushdown”
- Multi-dimensional access method (MDAM)
- Composite key support
- Secondary index support
- Table structure optimizations
- Salting of row-keys for workload balancing
Does Trafodion have full text search capabilities?
Trafodion provides SQL search capabilities using search functions such as POSITION (equivalent to INDEX) and SUBSTRING. Once large object (LOB) support is made available, a user-written or third-party UDF could be plugged in to add search capabilities into documents and images. This is a great area for community contribution.
Transactions
Is Trafodion’s transaction management an eventually consistent model?
No, Trafodion supports full ACID properties. Distributed Transaction Management provides transaction consistency across multiple row updates, updates across multiple tables, and transactions spanning multiple update statements. At the return from a COMMIT WORK statement, all rows and tables are in consistent form with regards to that transaction.
Does Trafodion provide transaction management for native HBase tables?
Yes, Trafodion supports transaction management for native HBase tables.
Does Trafodion support read consistency?
Yes, all the reads in Trafodion are completely consistent.
Does Trafodion offer ability to rollback transactions?
Yes, Trafodion offers full ACID protection across multiple SQL statements, tables, or rows. Transactions can be aborted using the ROLLBACK WORK statement.
Is there a transaction log and can the log be shipped to a DR site?
Not really. There are two logs that the transaction manager uses to coordinate transaction history, one at an HBase regionserver level and the other at the transaction manager level. But there is no support for shipping and replaying these logs on a remote DR site in a transactionally consistent manner.
Does Trafodion support distributed transaction management across multiple data centers?
There is no support for transaction management between Trafodion instances in different data centers.
How does two-phase commit scale linearly on large clusters?
Trafodion employs a Distributed Transaction Manager (DTM) model where a DTM runs on every datanode and each DTM works with its peers in other datanodes to coordinate the two-phase commit protocol. For efficiency purposes, the DTM is invoked only when necessary:
- If the transaction involves only a single region, then two-phase commit coordination is not necessary.
- The DTM is not involved with read-only transactions.
- The DTM is not involved in loading data into empty tables or during index creation.
- If the transaction impacts only a single table row, then standard HBase ACID protection is used instead of the DTM right now. In the future,these transactions might be fast-tracked using a different mechanism.
Hadoop Integration
Does Trafodion work as a Hadoop Yarn application?
Trafodion has not been tested with Yarn yet, but there is nothing in Trafodion that precludes it from being treated as a regular application running in a Yarn container.
Can Trafodion access Hive stored data?
Trafodion does provide the capability for SQL statements submitted to Trafodion to access, join, and aggregate a combination of Trafodion database objects, native HBase objects, and Hive tables (via the HCatalog).
Can we access Trafodion data with MapReduce?
While theoretically possible since Trafodion data is stored in HBase/HDFS, the data would not be easily interpreted due to the encoding mechanisms Trafodion employs for transaction performance and efficiency.
Trafodion provides automatic access parallelism without the need for writing MapReduce. If the optimized plan calls for parallel execution, the Trafodion Master process divides the work among Executive Server Processes (ESPs) to perform the work in parallel on behalf of the Master process. The results are passed back to the Master for consolidation.
In some situations where there a highly complex plan specified (for example, large n-way joins or aggregations), multiple layers of ESPs may be requested. See the diagram below.
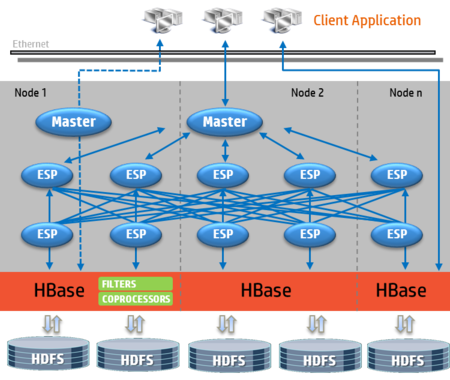
Can Trafodion data be accessed through Hive? Can we publish a Trafodion table to HCatalog and query it using Hive?
While theoretically possible since Trafodion data is stored in HBase/HDFS, the data would not be easily interpreted due to the encoding mechanisms Trafodion employs for transaction performance and efficiency.
Trafodion maintains its own catalog for metadata that provides the relational abstraction layer for accessing the physical storage layer via SQL commands. Trafodion objects are complex as they can have tables, indexes, views, constraints, which are represented in Trafodion’s own catalog. HCatalog can represent only simple objects like tables or column families currently but does not contain support for representing other more complex relational objects.
Alternatively, Trafodion data could be loaded into Hive/HDFS and then accessed using Hive specific operations or native MapReduce jobs.
Security
How is Database security management supported in Trafodion?
Currently, Trafodion provides security management based on HBase capabilities. There are projects as part of roadmap to provide full GRANT/REVOKE capability at the table and schema level for users and roles, along with support for directory based authentication.
Does Trafodion have role-based security authorization?
Yes, Trafodion supports ANSI GRANT/REVOKE on both an individual user and role basis. See Enabling Security Features in Trafodion. For details on the GRANT/REVOKE syntax, see the Trafodion SQL Reference Manual (pdf, 3.98 MB).
What is Trafodion’s security authorization granularity?
Trafodion supports authorization (that is, privileges) at the system and database-object level. System privileges are valid across SQL, such as the ability to create schemas and objects. Object privileges include tables, views, and other databse objects. Views can be used to restrict access to the subset of table rows referenced within the view.
Infrastructure
What hardware do I need to run Trafodion? Is it hardware vendor neutral?
Trafodion is designed to be hosted on vendor neutral, commodity hardware. As Trafodion runs on top of HBase and HDFS, a vendor’s recommended reference architectur such as HP Reference Architecture for Hadoop or similar server configuration is recommended as a starting point for a new installation.
Does Trafodion need to be installed on all the Hadoop cluster nodes?
Trafodion needs to be installed on all nodes that host an HBase RegionServer. Trafodion comes with an install script to make the installation process easy. For more information, see the Trafodion installation instructions.
What does Trafodion software require?
Trafodion software requires an x86-64 bit hardware platform running RedHat Enterprise Linux or CentOS 6.x kernel (64-bit). It supports Cloudera and Hortonworks Hadoop distributions; for details, see Supported Hadoop Distributions. The software is intended to be Linux and Hadoop distribution neutral, but other distributions have not been tested at this time.
Are there any recommended configurations in terms of nodes, memory, etc.?
Recommended sizings for Trafodion are still being developed, and vary based on the amount of data, anticipated query workload (types, rates/respose times, concurrency) and the peak number of supported concurrent connections).
What’s the process like when we add a new node to the cluster? Does the system grow elastically? The underlying HBase/HDFS infrastructure supports elastic scalability allowing for incremental node expansion, that is, datanode expansion. Trafodion could then access the HBase tables (or ‘regions’ of the HBase tables) that now span the new node(s). Trafodion services (that is, connection, compiler, master, ESP) can be made to leverage these additional nodes by restarting Trafodion with a new coniguration.
Does Trafodion need dedicated hardware?
Trafodion can run on dedicated hardware, cloud or VM configurations. For best and consistent performance, dedicated hardware is recommended where feasible.